ART User Guide
What is ART?
The Assisted Referral Tool (ART) was developed by the NIH Center for Scientific Review (CSR) to recommend potentially appropriate study sections based on the scientific content of a user's grant application. The information provided to ART is only used to recommend study sections and is not stored or persisted. The recommendations are solely for the benefit of the user.
Choosing the Mode of Operation
When you enter the ART landing page, you are asked questions to choose the operating mode:
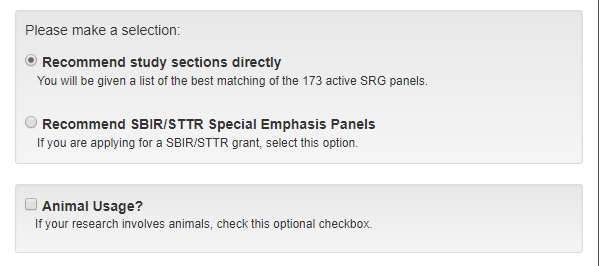
There are three modes of ART: recommending study sections, recommending SBIR/STTR Special Emphasis Panels and recommending Fellowship study sections. These modes involve different models trained independently.
The Animal Usage checkbox filters the list of potentially relevant study sections. If checked, study sections with less than 5% animal research are omitted from the search.
Extracting Scientific Concepts
When you enter your application text and title, the text is indexed in two ways. First, the RCDC ERA UberIndexer extracts scientific concepts from the RCDC Thesaurus and weights them according to their frequency in the text. Concepts in the title are given full weight. Second, a novel indexing scheme based on a self-learned dictionary of n-grams captures new concepts not found in the thesaurus. The two indices are concatenated into a single vector representing the text. All grant applications used to train the models are similarly indexed. ART does not store the documents or their indices; only the model representations are retained. Your text and indices are discarded when the job is complete.
For more on RCDC, visit https://report.nih.gov/rcdc/index.aspx.
Recommending Study Sections
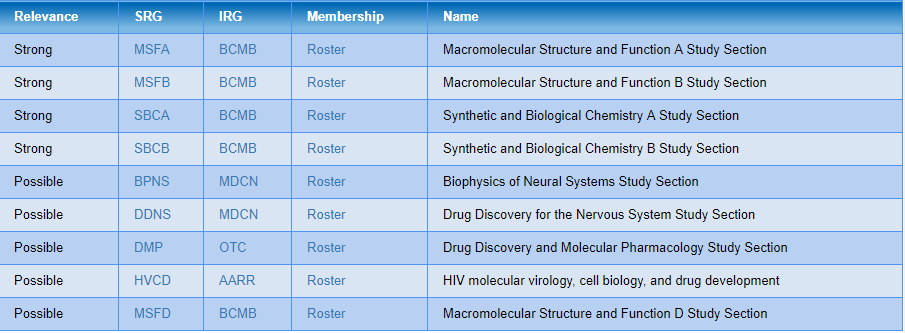
The vector representing your textâs concatenated index is sent to the bank of models (or fewer for SBIR/STTR SEPs and Fellowships), each voting on the more appropriate study section. Study sections are ranked by the number of pairwise votes received. Criteria determine how many (generally three to six) study sections are classified as "Strong" relevance and how many as "Possible" relevance. Within these groups, study sections are listed alphabetically.
In the example below, four study sections are listed in the "Strong" group and five in the "Possible" group. Links to the SRG, parent IRG descriptions, and SRG roster are provided for each study section. Users are encouraged to browse these links to determine if the recommended study sections match their research.
Tips for Using ART
- Entering the Title is optional but strongly recommended ART can operate without a title, but this is not recommended. Scientific concepts in the title are given full weight by the ERA RCDC UberIndexer, matching the indexing scheme of training applications.
- Entering both Abstract and Specific Aims is recommended More text improves performance. ART ignores stop words like "Abstract" and "Specific Aim." Include both sections from your application, but avoid including other sections, as ART does not filter them based on headers.
- Minimum text requirement ART requires at least 10 scientific concepts from the RCDC Thesaurus to be identified from the combined title and main text. This threshold ensures accurate classifications by providing a strong enough signal to overcome potential noise.
Keeping ART Updated
As CSR updates its study sections, ART is updated with new models for new study sections and retires models for phased-out ones. Three or four new releases of ART are issued per year. For new models to be accurate, sufficient application assignments to the new study sections are needed. If too few assignments are available, ART may use business rules to redirect recommendations from retiring models to new study sections until the new models are robust. Each release undergoes comprehensive testing and validation across all study sections.


